Data Pipelines & Retrieval-Augmented Generation
Published 8/2025
Created by Starweaver Team
MP4 | Video: h264, 1280x720 | Audio: AAC, 44.1 KHz, 2 Ch
Level: Intermediate | Genre: eLearning | Language: English | Duration: 45 Lectures ( 2h 47m ) | Size: 2.3 GB
Construct enterprise-grade data processing pipelines with quality validation and AI-ready formatting.
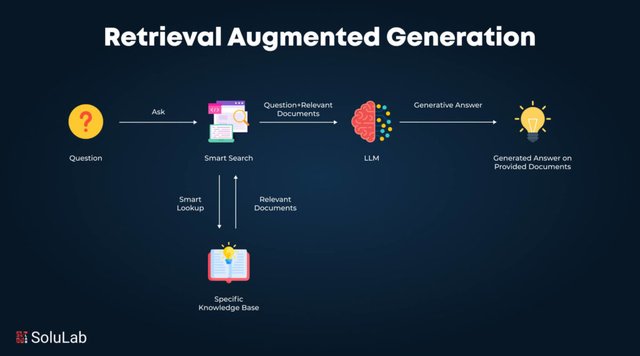
Implement sophisticated RAG architectures with vector search, embeddings, and context management.
Deploy advanced RAG optimization techniques including reranking, metadata filtering, and adaptive strategies.
Develop specialized customer support RAG systems with context-aware personalization and performance tracking.
Requirements
To get the most out of this course, learners should have a strong foundation in Python programming, along with familiarity in working with databases and data processing workflows. A solid understanding of machine learning principles is essential, as is experience with APIs and web services. Exposure to cloud-based infrastructure and tools will also be highly beneficial for the hands-on implementation of RAG systems and data pipelines.
Description
Course Description: Ready to make AI systems work with your organization's unique knowledge and data? Most AI implementations hit a wall because they can't effectively access, process, and utilize enterprise information, leaving vast potential untapped and organizations frustrated with generic responses.This specialized course transforms you into an expert data engineer who can build sophisticated RAG (Retrieval-Augmented Generation) systems that seamlessly bridge AI models with your organization's knowledge assets. You'll master advanced data processing pipelines that transform raw documents into AI-ready formats, architect high-performance vector databases for semantic search, and implement intelligent retrieval strategies that deliver contextually perfect responses. Through comprehensive hands-on labs, you'll build enterprise-grade RAG systems with adaptive orchestration, context-aware personalization, and production-ready monitoring.By the end of this course, you'll confidently deploy RAG solutions that revolutionize how organizations access and utilize their information, create intelligent knowledge management systems that scale to millions of documents, and implement customer support applications that provide instant, accurate answers from your proprietary knowledge base. You'll have mastered the critical bridge between raw enterprise data and intelligent AI applications.Join the specialists building the intelligent information infrastructure that makes AI truly valuable and become the RAG architect every knowledge-intensive organization desperately needs.Target Audience

ata Engineers transitioning to AI systemsML Engineers focusing on data pipelinesSoftware Engineers building knowledge systemsAI/ML Specialists implementing RAG solutionsPrerequisites:Completion of Course 1: GenAI Foundations and Prompt EngineeringPython programming proficiencyUnderstanding of databases and data processingBasic knowledge of machine learning conceptsExperience with APIs and web servicesMain Outcome: Learners will be able to architect and deploy end-to-end RAG systems with advanced data processing pipelines, vector databases, and intelligent retrieval strategies for enterprise knowledge management applications.Learning Objectives:Construct enterprise-grade data processing pipelines with quality validation and AI-ready formatting.Implement sophisticated RAG architectures with vector search, embeddings, and context management.Deploy advanced RAG optimization techniques including reranking, metadata filtering, and adaptive strategies.Develop specialized customer support RAG systems with context-aware personalization and performance tracking.Key Takeaways:Enterprise data pipeline engineering for AIProduction RAG system architecture and optimizationVector database management and semantic searchContext-aware customer support automationSkills Gained:AI Data Pipeline EngineeringAdvanced RAG System DevelopmentVector Database ArchitectureIntelligent Knowledge Management
Who this course is for
This course is designed for technical professionals working at the intersection of data and AI. Ideal participants include data engineers transitioning into AI workflows, ML engineers focused on robust data pipelines, software engineers developing intelligent systems, and AI/ML specialists implementing Retrieval-Augmented Generation (RAG) architectures. The curriculum speaks directly to those building or maintaining production-grade systems where data integrity, contextual awareness, and performance are critical.